Reward Models
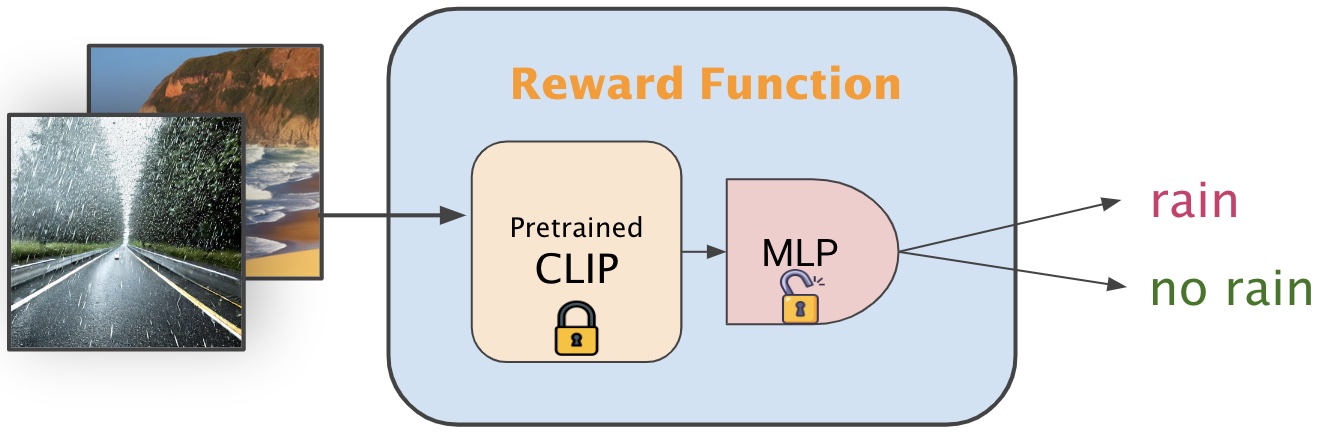
Given conditional images, reward models can perform regression or classification tasks and output the corresponding reward scores.
In recent advancements in text-to-image synthesis, fine-tuning diffusion models through reward-driven backpropagation has shown promising results. In this work, we introduce a framework for implementing and applying various reward functions to align text-to-image diffusion models according to specific visual characteristics. Our methodology involves training reward models capable of distinguishing unique image features—such as the presence of snow, rain, and pixelate—and using these models to guide the diffusion process towards generating images with desired attributes. We present a versatile tool that allows users to create custom reward models, facilitating personalized image generation. Through extensive experiments, we demonstrate the effectiveness of our reward models in producing high-fidelity, attribute-specific images. Our work not only extends the capabilities of text-to-image models but also provides a scalable platform for community-driven enhancements in image generation.
Given conditional images, reward models can perform regression or classification tasks and output the corresponding reward scores.
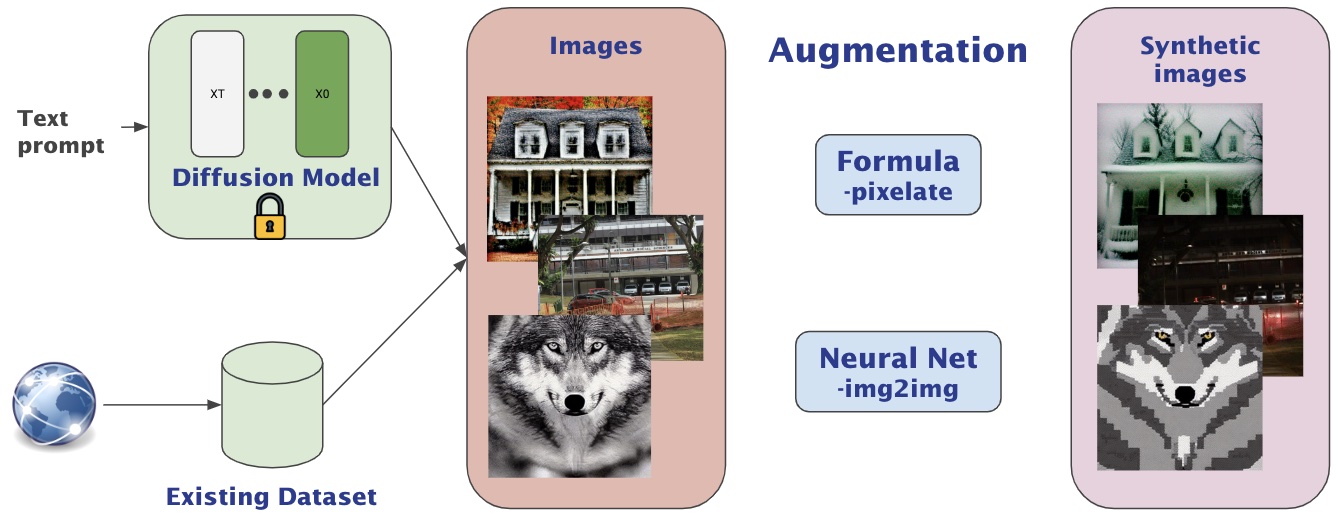
The success of reward models in guiding diffusion processes heavily relies on the quality and relevance of the training data. To populate our training datasets, we employ two primary methods, each suited to the specific requirements of the target attributes. For attributes that can be systematically generated through straightforward mathematical formulas, such as image size, or through simple transformations, such as pixelation (where images are resized to a smaller scale and then scaled back), we utilize stable diffusion models. This approach allows us to efficiently produce a large volume of accurate and diverse images tailored to the mathematical and transformational characteristics necessary for training. Conversely, when the desired attributes involve more complex changes, such as environmental alterations or video temporal coherence, the reliance on existing datasets becomes indispensable. These datasets may consist of real images, providing naturalistic examples of environmental conditions, or synthesized images, offering controlled variations ideal for training models to recognize subtle temporal dynamics. Both real and synthesized datasets are crucial as they equip the reward models with the robustness needed to handle a variety of real-world applications. In summary, our strategy for data generation leverages both synthetic image creation via diffusion models and the utilization of comprehensive existing datasets, ensuring that our reward models are trained on a spectrum of data that spans from simple transformations to complex environmental and temporal variations.
We employ AlignProp to fine-tune the diffusion models based on these reward functions. This approach will enhance our ability to effectively control the behavior of the models, enabling them to better align with desired objectives. The below results aligned with our expectations, as the images generated by the diffusion model with gradients fine-tuned by the reward model exhibited desired effect compared to the original images. Please move the slider to visualize results with different epochs.








